
Paper link | Note link | Code link | NeurIPS 2023
Paper title: Fine-grained Late-interaction Multi-modal Retrieval for Retrieval Augmented Visual Question Answering
這項研究針對知識基礎視覺問答中的兩個主要限制進行探討:
知識基礎視覺問答(KB-VQA)的任務利用外部知識來回答基於視覺內容的問題。
一種被稱為檢索增強視覺問答(RA-VQA)的框架能有效地解決這一任務。
本研究旨在解決 RA-VQA retriever 中的兩個限制:
知識基礎視覺問答(KB-VQA)旨在讀取影像並回答與影像內容相關的問題。
如何才能正確回答問題?
這取決於能夠檢索相關資訊並根據檢索到的知識生成答案的能力。
一種名為檢索增強視覺問答(RA-VQA)的框架專門為此任務而設計。
整體 RA-VQA 的運行過程:
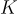 篇文件。
篇文件。
一個共同訓練的知識檢索和答案生成框架:
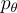 和 generator
和 generator 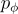 。
。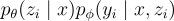 。
。這項研究討論了 RA-VQA retriever 中的兩個主要限制:
本研究提出了一種名為 細粒度後互動多模態檢索(FLMR) 的方法來解決這兩個限制:

這個框架包含兩個 encoder:視覺模型 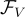 和語言模型
和語言模型 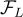 。
。
本研究使用兩種類型的視覺特徵:
對於第二種特徵來源,本研究使用 VinVL 來定位 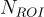 (Region-of-Interest)邊界框。
(Region-of-Interest)邊界框。
通過視覺模型 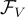 ,他們從影像
,他們從影像 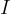 中獲得一個全局影像潛在特徵
中獲得一個全局影像潛在特徵 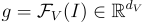 。
。
此外,他們還獲得基於 ROI 的潛在特徵 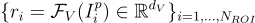 。
。
使用多維嵌入來提高檢索效果。
來自文本和視覺數據的 token-level 嵌入被串接以增強性能。
為了對齊不同模態的特徵,他們訓練了一個映射網路  。它學習將來自
。它學習將來自 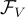 的視覺特徵投影到語言模型
的視覺特徵投影到語言模型 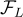 的潛在空間中。
的潛在空間中。
最終的查詢嵌入 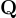 為:
為:
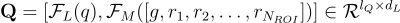
其中 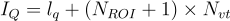 ,
, 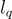 是問題
是問題 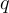 的長度。
的長度。
本研究計算 question-image pair 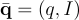 和文檔
和文檔 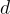 之間的相關性分數:
之間的相關性分數:
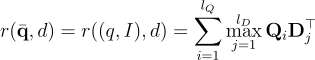
其中 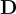 是來自知識庫的嵌入,
是來自知識庫的嵌入,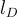 是文檔
是文檔 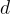 的長度。
的長度。
在本研究中,answer generator 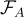 具有參數
具有參數 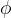 ,將根據檢索和答案生成的聯合概率從最佳候選中生成答案。
,將根據檢索和答案生成的聯合概率從最佳候選中生成答案。
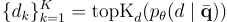
其中 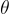 是
是 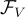 ,
, 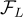 和
和 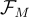 的模型參數。
的模型參數。
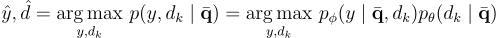
對於 retriever,本研究使用對比損失 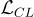 :
:
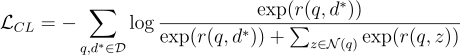
其中 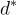 被認為是對於
被認為是對於 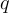 的負例。
的負例。
對於 answer generator,他們使用交叉熵損失來評估生成的序列:
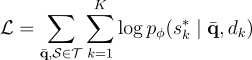
其中 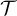 是整個數據集,
是整個數據集,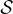 是人類回答的集合,而
是人類回答的集合,而 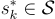 是在文檔
是在文檔 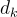 中最常出現的字符串。
中最常出現的字符串。
Backbone model:
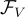 : CLIP ViT-base
: CLIP ViT-base
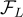 : ColBERTv2
: ColBERTv2
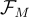 : 2層多層感知器
: 2層多層感知器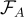 : T5-large / BLIP2-Flan-T5-XL
: T5-large / BLIP2-Flan-T5-XL
以下是模型在視覺問答數據集 OK-VQA 上的性能:

在 GoogleSearch(GS) 和維基百科上的檢索性能:

比較一些模型變體的案例研究:


 iThome鐵人賽
iThome鐵人賽